

A Semantic Approach to Structuring Social Tags
Abstract
Social bookmarking is rapidly emerging as a tool for users to associate subjective descriptions (tags) to web pages, which help them organize and recall information of interest. The association of documents, tags and taggers represents a wealth of information that can be exploited. By explicitly capturing and representing tag semantics in a taxonomy or ontology, the information structure of user tags is revealed, thus, facilitating machine understanding of user interests. Ontologies induced from folksonomies allow users to visualize and navigate through the information structures in the tag space and discover semantic relations between tags.
In order to overcome the problems associated with folksonomies such as ambiguities and lack of hierarchical structure, we use a natural language processing (NLP) technique to extract the relationships between tagged documents, tags and users in order to build structural knowledge on which applications could be developed. A rich set of semantic relations like ISA, PART_WHOLE, CAUSE, PURPOSE, MANNER,POSSESSION, TIME, LOCATION, and SIMILARITY are automatically identified in tags as well as in marked documents. Ontologies are constructed using these semantic relations.
1. INTRODUCTION
Folksonomies are unsystematic, unsophisticated collections of keywords associated by social bookmarking users to web content. Despite their inconsistencies, their popularity is increasing among Web users and enterprise employees. Originally intended for easy retrieval of documents, folksonomies now link documents to a social context and show how a series of people perceive documents. The association of documents, tags and taggers represents a wealth of information that can be exploited to facilitate advanced applications.
The tags represent personal marks on documents that can be mined to find out information about users. Folksonomies offer a unique insight into the mind of users, what is important to them, and how accurate they perceive a document content. It may be possible to determine user profiles from the history of their tagging activity and the marks they leave behind.
Folksonomies are shared among users enabling the discovery of new resources. By searching for documents labeled with a given tag, users may locate other documents of interest. This is extremely useful for objects with no other metadata, including photos, audio files, or videos which will typically not be retrieved by text-based search engines. By glancing at the set of tags associated with a document, users may identify related topics that interest them. Furthermore, tag clouds – visual representations of tags, which provide a weighted view of the folksonomy – pinpoint the topics of interest of the social bookmarking community. These benefits are immediate to social bookmarking users and help reinforce and encourage more tagging.
However, folksonomies are flat without any hierarchy or relationships between its tags. Moreover, tags are ambiguous as different users apply terms to documents in different ways. The users’ uncontrolled vocabulary includes different types of variations and ambiguities. For instance, tags are case insensitive, use space or punctuation as delimiters, have both singular and plural forms, same tag applied to different contexts, and others.
In order to overcome these problems, we propose a novel natural language processing (NLP) technique that structures folksonomies by exploiting the tags, their social bookmarking associations and, more importantly, the content of labeled documents. We show that semantically rich ontologies can be built from folksonomies by employing NLP tools and automatic ontology generation technologies. Our method makes social bookmarking annotations valuable not only to their users, but also to automated systems.
The approach is to normalize the lexical, syntactic, and semantic variations of folksonomic tags, and to identify semantic relationships between the tags, which include PART_WHOLE, CAUSE, PRODUCE, SIMILARITY, DOMAIN and other relations. A consolidated ontology that unifies the folksonomy’s semantic information with knowledge extracted from bookmarked documents provides semantic links between documents as well as between tags and documents that enhance the social bookmarking annotations.
Once this consolidated ontology is exported into OWL/RDF formats, these relationships can be exploited by semantic technologies applications. One such application is to enhance personalized search to take advantage of social bookmarking information while scoring information relevancy based on user’s interests. User satisfaction is immediate without the need to disambiguate polysemous query terms. Moreover, even without expressing an information need, users may receive automatic up-to-date tag, document, or user recommendations generated by the proposed system, thus, improving the user’s ability to discover new resources.
2. Technical Approach
In order to derive a rich semantic representation of the folksonomic tags, we first normalize the lexical, syntactic, and semantic variations present in the folksonomic data. For this purpose, we exploit not only a tag’s textual information, but also its associations with other tags and with documents as created by users as part of the social bookmarking data. Once each tag’s meaning is captured in a rich semantic representation, we identify a series of classification procedures that produce numerous tag-tag relationships that complete the ontology induced from the flat lexicon of folksonomic tags. SYNONYMY,ISA,PART_WHOLE,SIMILARITY,DOMAIN,ATTRIBUTE, and other relations between tags expose the folksonomy’s ontological organization.
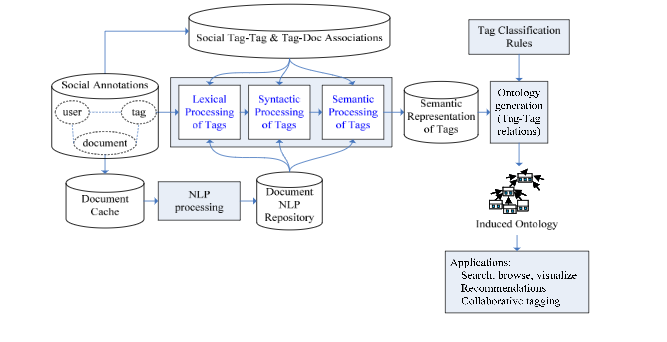
Fig. 1. System architecture
In Figure 1, we show the architecture of our prototype system, which implements the mechanisms of deriving semantic structures from folksonomies.
For this project we used social bookmarking data collected from the del.icio.us bookmarking service (http://delicious.com) that allows users to tag, save, manage, and share web pages from a centralized source. Our initial dataset is stored in a MySQL database and can be browsed using the Scuttle social bookmarking tool (http://sourceforge.net/projects/scuttle). It includes all (user, document, tag) social annotations stored publicly in del.icio.us between May 19th and June 4th, 2009.
Since our goal is to show the feasibility of our approach, all our experiments were performed on a smaller dataset, described in Table 1, dataset created from the social bookmarking information collected from Delicious.

Defining a Semantic Structure for Folksonomies
Folksonomies are collections of tags. Thus, our initial efforts in designing a formal representation of folksonomies focused on the tags and their representation. For each tag, we create a rich semantic representation that captures the concepts mentioned in the tag text and their semantic relations. Therefore, each tag becomes a rich semantic graph that can be easily exploited during the process of organizing the tags (transforming the folksonomy into an ontology). We show several examples in Figure 2

Each concept part of a tag representation is linked to its corresponding WordNet synset. For example, american|JJ|1 is part of synset id 02927512. These links enable the system to identify synonyms that denote the same concept in WordNet. Each tag is accompanied by certain metadata, which includes language information, bookmarking information, certain count/frequency statistics, etc.

In Figure 3, we display the SYNONYMY cluster of {cognition, knowledge} with their corresponding links to the original folksonomic tags that map to this cluster and their associated social bookmarking data information (for each tag, we list several (user, document) pairs where user assigned tag to document). The SYNONYMY clusters groups a set of normalized tags – semantic representations of folksonomic tags – derived using the tag understanding procedures.
At the folksonomy level, semantic relations, such as ISA, PART_WHOLE (PW), SIMILARITY (SIM), etc. link the tags, inducing a rich semantic structure for the given folksonomy. Folksonomies are represented as rich semantic graphs whose links are the semantic relations that connect the tags forming the folksonomy, which constitute the nodes of the representation. For semantically equivalent tags, a single semantic representation is used and corresponding normalization links make explicit these tag connections.

In Figure 4, we display a portion of a folksonomic structure. Its nodes are the SYNONYMY clusters detailed in Figure 3 (here, we display only the set of synonymous normalized tags). The links represent the semantic relations identified between the tags using the classification procedures.
3. Extracting Tag Semantics
The process of understanding tags is broken down into several different linguistic processing steps. Each stage uses three sources of information that provide complementary information to our prototype system: (1) the tag space of the folksonomy : the text of each tag is used to derive information about the tag, (2) the social bookmarking data: tag associations augment and refine the initial understanding of a given tag, and (3) the content of textual documents: situating a tag within the larger semantic context of the documents it was assigned enhances the existing understanding of a given tag. The various linguistic processing steps we implemented as part of the process of capturing tag semantics can be classified as lexical, syntactic, and semantic.
Lexical understanding of tags
The lexical understanding of a tag includes the following stages: spelling corrections, tokenization and capitalization restoration.
The process starts by verifying whether the tag is a single token. If a tag was found among the words that constitute the vocabulary of a language, it is a single token. If it was not found, then (1) the tag contained two or more words glued together – these should be tokenized/separated for a correct understanding of the tag semantics, or (2) the tag was indeed a single token, but it was spelled wrong by the social bookmarking user, or (3) a combination of (1) and (2). Therefore, for each unmatched tag, we generate a list of correctly spelled candidates by measuring the edit distance between the tag text and a language vocabulary and selecting only the words with a minimum edit distance. In addition, depending on the length of a tag, we attempted to break the tag into multiple vocabulary words. Each candidate generated by the spell checking and tag splitting processes is scored based on how well it matched tokens within the content of the documents that were labeled with this tag. Furthermore, the scores of spelling variations that were used as (i) tags to label documents to which this tag was assigned or as (ii) tags by the users that also made use of this tag were boosted. For all cases where a tag was split into multiple words, we scored the phrase generated by the splitting process using the probability values of English bigrams. Thus, phrases created by the split of the tag text into random words that do no ‘go together’ were scored lower than valid English phrases. Once this process was complete, the highest scoring variation of the tag text was used for further processing.
In order to restore the proper capitalization of tags that may denote proper names, we compare each tag text with the content of the documents that were labeled using that tag. We note that the document content includes the correct spelling and capitalization information for a tag. We also extend these comparisons to the titles of the labeled documents. For this processing step, we computed a likely capitalization for the tag based on all the documents labeled with the given tag. If a tag is not found within the content of a document, the system fell back to the capitalization computed across all documents. Any competing values for a tag’s capitalization are scored based on the position of the candidate within a document (English headlines capitalize the initial letter of all their content words; Sentences begin with a capitalized word regardless of the correct capitalization of the word). For an accurate understanding of the folksonomic tags, the capitalization of a tag plays an important role during the process of identifying whether the tag is a named entity as well as the class to which the tag belongs to. This is true for tags taken as a whole as well as for words or phrases that are part of a tag.
Examples of tags modified by this processing step include: linux→ Linux, xhtml → XHMTL, bbq→BBQ, javascript → JavaScript, diy → DIY, christian_fiction → Christian fiction, amish→ Amish, twitter, → Twitter, bradley/colin → Bradley / Colin, latex → LaTeX, etc.
Syntactic understanding of tags
All English tag phrases (as resulted from the lexical understanding step) are processed using the part-of-speech tagger, sentence boundary detector, and syntactic parsers (a chunk parse followed by a full syntactic parser).
For the part-of-speech tagging step, preference is given to the NOUN part-of-speech for single word tags, which cannot be tagged within a context. Ambiguities were also resolved by selecting the part-of-speech of the tag as it was marked within the content of the documents labeled with that tag.
The sentence boundary detection step is part of our processing pipeline. It did not modify its input in an overwhelming majority of cases (very few tags spread across sentences).
The syntactic parsing step processed tags with more than one token. This process identifies the type of the tag phrase (NP = noun phrase, VP = verb phrase), its syntactic head as well as any syntactic dependencies between the tag’s constituents. This information was later used by our semantic parser as well as the ontology generation procedure.
We list below several non-trivial examples: ushistory → US history → US/NNP history/NN → (NP (NNP US) (NN history)) 10.000+words → 10.000 words → 10.000/CD words/NNS → (NP (CD 10.000) (NNS words)) to read→to read→to/TO read/VB → (VP (TO to) (VB read))
Semantic understanding of tags
The semantic understanding of tags stage covers the understanding of abbreviations and acronyms, the sense disambiguation of tags and the discovery of semantic relations within multi-word tags. The first two processing steps are the most challenging ones, as they require a broad context for the tag usage. To disambiguate abbreviations we used a compiled abbreviations dictionary which comprises of 118,055 distinct abbreviations. Given the various possibilities for defining, thus disambiguating an abbreviation, we rely on the tagged document content to determine the correct domain of the abbreviation. For this purpose, we attempt to link important document concepts to domain descriptions using lexical chains built using WordNet’s synset-synset relations. Short chains always indicate strong semantic similarities between the connected concepts, and, thus, the document’s subject belongs to a particular topic. Using this information, we narrowed down the set of possible interpretations of the tag. Further disambiguation is done using co-occurring tags and their meanings. Also, by aligning the abbreviation text with the document content (more specifically, its list of simple noun phrases), new definitions for abbreviations are accurately identified and associated with the tags.
For instance, in our dataset collected from the www.delicious.com website, tag PR is used to label 1409 documents. In our dictionary, there are 87 distinct definitions for this abbreviation, including, Press Release, Public Relations, Puerto Rico, Page Rank, Public Radio, Permanent Resident/Residency, etc. The contents of the documents labeled with this tag are vital to the semantic understanding of the abbreviation.
The second step in our semantic understanding process continues the disambiguation process with a multi-stage approach to tag sense identification which assigned each tag or tag concept its corresponding WordNet sense number. For this step, we rely on the content of the documents labeled with the tag. The word sense disambiguation process exploits the linguistic context of the analyzed word. Within documents, this includes the words surrounding the input concept. However, for folksonomic tags, the documents that social bookmarking users labeled provide the needed linguistic context. For tags that appear within their corresponding documents, we use the sense numbers derived by our word sense disambiguation module during the semantic processing of the documents. For instance, tag sign used to label http://www.signingsavvy.com (Signing Savvy: Your Sign Language Resource) occurs in the document content and its linguistic context on sign language, American sign language, fingerspell, etc. pinpoint to its WordNet sense number 9 (a gesture that is part of a sign language). This sense value is also assigned to the tag concept.
For single-word tags, the word sense disambiguation processing step produces a semantic representation of the tag and the system is now able to use the extracted information to link the tag with other tags as part of the ontology building process.
4. From Tag Semantics to Ontological Structure
Once the process of understanding what each tag represents is completed, we shift our focus to the derivation of the folksonomy structure from the tag semantics. We begin by connecting tags using EQUALITY and SYNONYMY relations.
EQUALITY relations were created between tags with the same lemma, part-of-speech, and sense number. These are relations connecting highly correlated tags. Non-trivial examples include: EQUALITY(activity, activities), EQUALITY(after-effects, AfterEffects), and EQUALITY(opinion, Opnion). In addition to the linking identical tags assigned to multiple bookmarks, this relation type links tags that are syntactically normalized to the same form, tags that are tokenized (including capitalization) to the same form and misspelled tags to their correct form tags.
SYNONYMY relations were assigned to pairs of tags that have the same synset id. These tags belong to the same synset in WordNet (for single word tags), thus deemed synonyms within WordNet. The synset id is derived based on the lemma, part-of-speech and sense number of the tag. For instance, tags Archeology and Archaeology are part of the same WordNet synset (id: 06144081); OS and operating.system are synonyms within a WordNet synset (id: 06568134). Furthermore, we used the named entity and abbreviation information to identify SYNONYMY relations between tags that refer to the same concept using different wordings. This is extremely useful for non-WordNet concepts. Examples includes SYNONYMY(LA, losangeles), SYNONYMY(nyt, nytimes), etc.
In addition to EQUALITY and SYNONYMY relations, automatic procedures that derive additional tag-tag relations were implemented. An initial set of ISA relations was created between all named entity tags and their corresponding WordNet synsets that describe the name of the entity class. For instance, there is an ISA relation between tags OracleCorporation and organization. Another example includes ISA(davidfosterwallace, person). We note that most named entity tags are not defined within WordNet and these ISA relations are vital in describing the hierarchical structure of the folksonomy. These relations denote a directional semantic subordination of their arguments.
By mapping our SYNONYMY clusters to WordNet, we were able to add to our ontology existing WordNet relations that link two folksonomic tags. This procedure added 23.66% of the total number of relations to the ontology. Examples include ISA(vegan, vegetarian), ANTONYMY(peace, war), PART_WHOLE(Businesses, markets), ENTAIL(proofreading, +read), SIMILARITY(important, general), and DOMAIN(light, physics).
For complex tags, we used their semantics to find related tags. For instance, for tags of the form modifier head where there is a semantic relation between modifier and head relation and where head constitutes a folksonomic tag, we add an ISA relation between the modifier head and head tags. The relation linking modifier and head can be a PROPERTY_ATTRIBUTE, PART_WHOLE and even a TEMPORAL relation. Examples include ISA(book-cover, covers), ISA(theoryofmind, theory), and ISA(photoshoptutorials, tutorials,).
The resulting ontology is a rich graph with nodes that represent clusters of synonymous tags and labeled directed links that denote the semantic relations that connect the folksonomic tags. Projections of this graph, which include only relationships such as ISA and PART_WHOLE, reveal hierarchical organizations of the folksonomy.
Experimental Results
This system was tested on a folksonomy of 8,460 tags built from a subset of social bookmarking data collected from the del.icio.us bookmarking service (www.delicious.com) between May 19th and June 4th2009. The resulting folksonomic ontology includes 8,762 nodes (semantic representations of synonymous normalized tags – we show an example in Figure 2) and 8,668 ontological links (semantic relations between tag SYNONYMY clusters).
The evaluation conducted for this prototype system focused on (1) the tag understanding process and (2) the tag-tag relation generation step. Table 2 shows the accuracy of the various stages of the tag-understanding step. Most errors occur when tags cannot be identified within their corresponding documents. Propagation errors from the capitalization restoration step account for future mistakes made during the part-of-speech tagging and named entity recognition stages.

Given a perfect input, the classification rules for deriving the ontological structure of the folksonomy deduce a highly accurate set of tag-tag semantic connections. However, because of the sense disambiguation errors, tags are placed into incorrect SYNONYMY clusters more than 17% of the time, affecting the relation generation process whose accuracy becomes 80.30%, as measured on a randomly selected set with 20% of the total relations (ISA – 6165, SIMILARITY – 957, PART_WHOLE – 683, etc.).
5. Related Work
Various research groups have proposed algorithms that attempt to structure folksonomies. First, analyses and comparisons of folksonomy with taxonomies and ontologies have emerged [4],[20]. Various models that conceptualize tagging activities were proposed [7],[9],[17],[10]. Approaches to tagging and folksonomies have been dominated by a focus on the statistical analysis of tag usage patterns [8], and information retrieval and navigation [11]. The links identified between tags cover few relations types, most notable “type of”, “aspect of”, and “same-as”. Support for spelling corrections as well as integration of morphological tools have not been addressed yet. Methods that exclusively explore the social bookmarking annotations, more specifically, the tag co-occurrences among resources and users were also investigated [19],[13]. These algorithms employ graph-clustering procedures to connect tags, which were used by the same users for the same resources. We note that no understanding of tags has been attempted.
Specia and Motta [23] present an approach for building an ontology from the folksonomic tags by clustering the tag space based on tag co-occurrence and mapping the tags and tag clusters into ontology elements. They use web searches and Wikipedia as resources to identify the concepts the tags and tag cluster correspond to and their relations. Zhang et al. [25] make use of URL-tag associations and create a probabilistic generative model that utilizes the probability of a user to encounter an URL, the probability the URL makes the user think of a concept, and the probability of the concept to trigger the user to use a tag. They develop statistical methods for modeling URL semantics and tag similarity and ambiguity. A complete binary hierarchy structure of the emerged concepts is built using HACM hierarchy clustering model.
Other studies propose an approach that combines the user-generated tag set with controlled vocabulary in order to develop an ontology [5]. The controlled vocabulary is used as the backbone of the new ontology, which will be expanded by the addition of folksonomic tags that are clustered based on similarity scores.
Efforts were made to develop ontologies that represent the structure and semantics of a collection of tags as well as social networks among users based on the tags. The SCOT (Social Semantic Cloud Of Tags) ontology was proposed [15].
Personalization of search results for a given user that uses an automatically generated tag ontology as a way to represent the user profile and infer his/her information needs has been used to demonstrate the quality of the folksonomic structure [24].
There have been efforts to recommend tags for documents based on their content. TagAssist [22] uses a keyword search index to model tag-document association. Tag suggestions for a target document are based on similar documents previously tagged as part of the social bookmarking data. TFIDF measures defined on document terms are used for determining document similarity.
6. Discussion
Social networking services and, more importantly, social bookmarking applications are part of Web 2.0 which is about “connecting people”. The benefits of social bookmarking services are: storing the user’s bookmarks in a public location accessible over the internet; allowing users to assign bookmarks their own tags, descriptions, or notes; enabling bookmark filtering by tags for easy access to relevant information; allowing users to browse other people’s public bookmarks, thus facilitating sharing of information and distributing the task of finding documents of interest. Their growing popularity demonstrates that these benefits outweigh their drawbacks such as lack of standards for the keywords and vocabulary used, for the structure of the tags – singular vs. plural, capitalization, spelling errors, sense ambiguity, and no explicit means to indicate hierarchical relations between tags.
Transforming folksonomies and unstructured text into structured, standardized knowledge will enhance information access, bridge the gap with the formal representations required by semantic technologies, and ease the use of social bookmarking systems to categorize and organize data.
An immediate and natural step is to enhance our prototype system to: (1) process non-English tags, (2) consider new sources of information in the tag understanding process, e.g., the tag-tag associations given by the users of the social bookmarking service, (3) distribute its computations across several computers ensuring scalability for real-world datasets, and (4) process social data in real-time as opposed to its current batch operations.
7. References
[1] Zharko Aleksovski, Warner ten Kate, and Frank van Harmelen. 2006. Exploiting the Structure of Background Knowledge Used in Ontology Matching. In Proceedings of the 1st International Workshop on Ontology Matching (OM-2006), collocated with ISWC-2006, Athens, Georgia (USA), 2006
[2] Mithun Balakrishna, Dan Moldovan, Marta Tatu and Marian Olteanu. 2010. Semi-Automatic Domain Ontology Creation from Text Resources. Submitted to the Seventh International Conference on Language Resources and Evaluation (LREC-2010), Valletta, Malta, 19-21 May 2010
[3] Brooks, Cristopher. H., and Nancy Montanez. 2006. Improved Annotation of the Blogosphere via Autotagging and Hierarchical Clustering. In WWW 06. Proceedings of the 15th international conference on World Wide Web, (pp.625-632.). New York: ACM Press
[4] Cattuto, Ciro, Christoph Schmitz, Andrea Baldassarri, Vito D. P. Servedio, Vittorio Loreto, and Andreas Hotho, et. al. 2007. Network Properties of Folksonomies. AI Communications 20(4), 245 - 262.
[5] Miao Chen and Jian Qin. 2008. Deriving Ontology from Folksonomy and Controlled Vocabulary. In Proceedings of iConference 2008. Los Angeles, California, February 2008.
[6] Damme, V.C., Hepp, M., & Siorpaces, K. 2007. FolksOntology: An Integrated Approach for Turning Folksonomies into Ontologies. ESWC 2007 “Bridging the Gap between Semantic Web and Web 2.0” workshop.
[7] Echarte, F., Astrain, J. J., Córdoba, A. and Villadangos, J. 2007. Ontology of Folksonomy: A New Modeling Method. In Proceedings of Semantic Authoring, Annotation and Knowledge Markup (SAAKM), CEUR Workshop Proceedings, 289, 2007.
[8] Golder, Scott A., and Bernardo A. Huberman. 2006. The Structure of Collaborative Tagging Systems. Journal of Information Sciences, 32(2), 198-208
[9] Gruber, Thomas. 2007. Ontology of Folksonomy: A Mash-up of Apples and Oranges. International Journal on Semantic Web and Information Systems, 3(2).
[10] Gruber, Thomas. 2008. Collective Knowledge Systems: Where the Social Web Meets the Semantic Web. Journal of Web Semantics 6(1), 4-13.
[11] Halpin, Harry., Valentin Robu, and Hana Shepard. 2006. The Dynamics And Semantics Of Collaborative Tagging. In Proceedings of the 1st Semantic Authoring and Annotation Workshop (SAAW06).
[12] Harry Halpin and Hana Shepard. Evolving Ontologies from Folksonomies: Tagging as a Complex System. http://www.ibiblio.org/hhalpin/homepage/notes/taggingcss.html
[13] P. Heymann and H. Garcia-Molina. 2006. Collaborative Creation of Communal Hierarchical Taxonomies in Social Tagging Systems. Technical Report 2006-10, Computer Science Department, April.
[14] A. Hotho, R. Jaschke, C. Schmitz, and G. Stumme. 2006. FolkRank: A Ranking Algorithm for Folksonomies. In Proceedings of the FGIR.
[15] Hak-Lae Kim, John G. Breslin, Sung-Kwon Yang, and Hong-Gee Ki. 2008. Social Semantic Cloud of Tag: Semantic Model for Social Tagging. In N.T. Nguyen et al. (Eds.): KES-AMSTA 2008, LNAI 4953, pp. 83–92, 2008
[16]Hak Lae Kim, Simon Scerri, John G. Breslin, Stefan Decker and Hong Gee Kim. 2008. The State of the Art in Tag Ontologies: A Semantic Model for Tagging and Folksonomies. In Proceedings of International Conference on Dublin Core and Metadata Applications 2008 (DC-2008), Berlin, Germany, September 2008.
[17]Knerr, Torben. 2006. Tagging Ontology - Towards a Common Ontology for Folksonomies. http://tagont.googlecode.com/files/TagOntPaper.pdf
[18]Lalwani, Saurabh and Huhns, Michael N.. 2009. Deriving Ontological Structure from a Folksonomy. In ACM-SE 47: Proceedings of the 47th Annual Southeast Regional Conference. Clemson, South Carolina.
[19]P. Mika. 2007. Ontologies Are Us: A Unified Model of Social Networks and Semantics. Web Semantics: Science, Services and Agents on the World Wide Web, 5(1).
[20]Elaine Peterson. 2006. Beneath the Metadata: Some Philosophical Problems with Folksonomy. In D-Lib Magazine, 12(11), November 2006. http://www.dlib.org/dlib/november06/peterson/11peterson.html
[21]P. Schmitz. 2006. Inducing Ontology From Flickr Tags. In Proceedings of the Collaborative Web Tagging Workshop (WWW06).
[22]Sood, S., Owsley, S., Hammond, K., and Burnbaum, L. TagAssist: Automatic Tag Suggestion for Blog Posts. ICWSM, 2007.
[23]Specia, L. and E. Motta. 2007. Integrating Folksonomies with the Semantic Web. In Proceedings of the European Semantic Web Conference (ESWC 2007), Innsbruck, Austria: Springer, 2007.
[24]Noriko Tomuro and Andriy Shepitsen. 2009. Construction of Disambiguated Folksonomy Ontologies Using Wikipedia. In Proceedings of the 2009 Workshop on The People’s Web Meets NLP: Collaboratively Constructed Semantic Resources (People’s Web). Suntec, Singapore, August 2009
[25]Lei Zhang, Xian Wu, and Yong Yu. 2006. Emergent Semantics from Folksonomies: A Quantitative Study. In S. Spaccapietra et al. (Eds.): Journal on Data Semantics VI, LNCS 4090, pp. 168–186, 2006