

Polaris: Lymba’s Semantic Parsing
1. INTRODUCTION
This paper presents Polaris, a semantic parser that takes free English text or parsed sentences and ex-tracts a rich set of semantic relations. Polaris ex-tracts semantic relations from a wide variety of lexico-syntactic patterns (Section 3), not only verb argument structures. Polaris will be freely available for research purposes1and can provide its output in several formats: XML, RDF triples, logic forms or free text. Polaris is also commercially available and it is at the core of many software developed at Lymba: question answering system(Moldovan et al., 2010), entailment recognition(Tatu and Moldovan, 2005), ontology creation (Balakrishna et al., 2010), etc.
Whereas syntactic parsers have matured during the last decade, the progress in semantic parsers has been more modest mainly due to the complexity of the problem. Role labelers extract only relations between a verb and its arguments, however a SemEval task has focused on relations between nominals. Working with semantics is harder than some other NLP tasks mainly because: (1) there is no agreement on the set of relations to extract; (2) relations are often poorly defined (a sentence and a couple of examples); and (3) relations can be encoded between a wide variety of arguments and syntactic patterns.
Polaris extracts semantic relations that are easily transformed into RDF triples, a standard for knowledge representation proposed by W3C and recommended for knowledge interchange within the se-mantic web. Its output can be readily used with third party RDF management tools such as Oracle11g and RDF reasoners such as AllegroGraph.
1http://www.lymba.com
2 Previous Work
There have been several proposals to extract semantic relations from text. The availability of large corpora has allowed the organization of competitions(Hendrickx et al., 2009; Pustejovsky and Verhagen, 2009; Ruppenhofer et al., 2009; Carreras and M`arquez, 2005). Polaris is a comprehensive effort to extract relations from text, blending previous efforts on relation extraction and incorporating inhouse annotations. Polaris is an unified, self-contained and ready-to-use tool and it is able to extract more relations than any other single tool available (Fig. 1).
Our approach to representing text semantics contrasts with first order logic and with work grounded on extensions of first order logic (Poon and Domingos, 2009). We believe that using a fixed set of dyadic relations is better suited for automated reasoning than allowing an uncontrollable large number of predicates with variable number of arguments.
A novelty of Polaris, that brings a significant improvement, is its feature of imposing semantic restrictions on relations arguments which in turn results in filtering our relations that can not exist be-tween certain arguments. It is grounded on an ex-tended definition for semantic relations that specifies semantic restrictions on the relation arguments.
3 Approach
Polaris aims at extracting semantic relations from a wide variety of lexico-syntactic patterns, including verb and arguments (John runs fast: AGENT(John, runs), MANNER(fast, runs)), nominals (door knob: PART-WHOLE(door knob,door)), genitives (Miranda’s house: POSSESSION(house, Miranda)), adjectival phrases (cat in the tree: LOCATION(in the tree, cat)), adjectival clauses (the man who killed Kennedy: AGENT(the man,killed)) and others.

Figure 1: Example of thorough semantic representation Polaris extracts. Only four out of fifteen relations are semantic roles, i.e., a relation between a verb and its arguments.
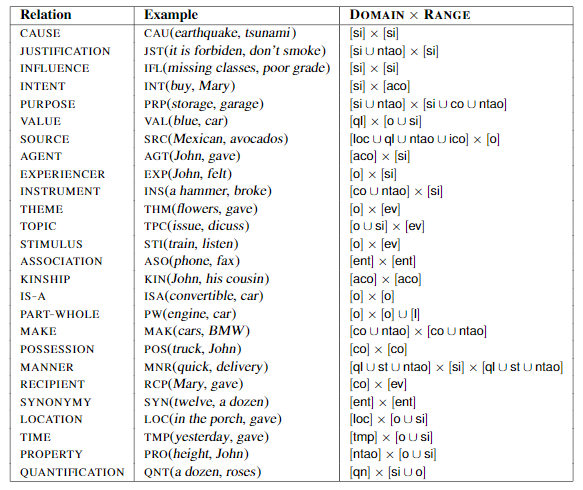
Table 1: Relation inventory used by Polaris. Domain and range restrictions are defined over the ontology presented in(Blanco et al., 2010).
FrameNet, NomBank, SemEval competitions) and our own annotations. Some relations considered elsewhere are ignored since they do not occur frequently enough in text and their automatic extraction would not be feasable, e.g., ENTAILMENT.
Polaris uses an extended definition for semantic relations. Whereas most relation inventories are de-fined using plain English and some examples, Polaris incorporates semantic restrictions on domains and ranges (i.e., what kind of concepts can be the first and second argument). These restrictions are defined in Table 1 using a modified version (Blancoet al., 2010) of an ontology first proposed by Hel-big (2005). Domain and range restrictions allow us
to select plausible relations that may hold between any pair of concepts (x,y) simply by enforcing that their semantic classes are compatible with the relation definition. For example, RANGE(INTENT) is restricted to animated concrete objects, thus, INTENT is not selected for the pair (x, wind) since an abstract object like wind cannot be the second argument of INTENT by definition.
4 Architecture
Polaris consists of the following main modules:
Pre-processing. POS tagging, NER, syntactic parsing, WSD, co-reference resolution.
Bracketer. A set of heuristics simplify parse trees and fix parse errors.
Argument Identification. Concept pairs likely to encode a semantic relation are selected based on lexico-syntactic patterns.
Domain and Range Filtering. Plausible relations are assigned to each pair based on their semantic classes and the definition of relations.
Grouping. Pairs are grouped into eight generic patterns: JJ,JN,JV,NJ,NN,NV,VN,VV.
Feature Extraction. Different features are extracted depending on the generic pattern.
Classifiers. SVM, Semantic Scattering(Moldovan and Badulescu, 2005), Decision Trees and Naive Bayes, both in a per-relation and per-pattern approach. Predicted relations for each concept pair are determined.
Conflict Resolution. Classifiers’ ouput is resolved and manually defined rules enforced. Final semantic representation is obtained.
Step 1 can be bypassed if the information has al-ready been extracted. The implementation allows the user to easily activate and deactivate a module, retrain exclusively for specific relations (commonly, the less relations the more accurate), focus on certain syntactic patterns and incorporate new annotation. Because of space constraints, this abstract only provides a cursory description of the above modules.
Pre-processing is done with in-house tools that obtain state-of-the-art performance. The bracketer is specially useful since we are not interested on obtaining perfect parse trees, but rather trees that help detecting which pair of concepts may hold a relation.
Argument identification is based on lexicosyntactic patterns. This step is key: in order to extract a relation R holding between two concepts, we must first detect whether or not the concepts are likely to encode any semantic relation.
Domain and range filtering is done in two phases. First, argument pairs are assigned a semantic class from the ontology. Second, the relations whose do-main and range are compatible with the semantic classes of the pair are selected as plausible relations.
Assigning a semantic class from the ontology to an arbitrary piece of text is not a trivial task. First, the head word of a potential argument is identified. Then, the head is mapped into a semantic class from the ontology using three sources of information: POS tags, WordNet hypernyms and named entity (NE) types. We obtained rules that define the mapping following a data-driven approach using a subset of the available data.
For this task, we do not use word senses because in our experiments it did not bring any improvement; all senses are considered for each word. Rules are of the following form:

Note that the above rule partially accounts form etonomy resolution. NE types like organization and location are mapped to animate concrete object even though they can be so only when metonomy is used, e.g., [The White house]organization/[Washington]locationpassed an important bill.
The next step is to group concept pairs into simplified syntactic paths. These groups are defined by the category of the head of the argument, J stands for adjective, N for noun and V for verb. This allow us to create models specialized on each pattern.
Feature extraction considers standard features for semantic relation extraction (syntactic path, first word, voice, etc), as well as features that we have identified over time. The latter include, among many others, the semantic class of modifier noun, useful to detect relations within genitives (Moldovan and Badulescu, 2005).
Finally, classifiers are used to determine which relations hold between the pairs of concepts. Because their output is not guaranteed to produce a coherent representation, a final step uses heuristics to tune the output. These heuristics assure that incompatible relations are not proposed for the same pair of concepts (e.g., if the classifiers predict both IS-A(doorknob ,knob) and PART-WHOLE(door knob, knob),the latter is discarded).
5 Results and Performance Analysis
Polaris uses as training corpora a mixture of publicly available resources (FrameNet, PropBank NomBank and SemEval competitions; their relations inventories were mapped to our inventory) and annotations done at Lymba over time. The latter include questions from several TREC competitions and text sources relevant to past projects at Lymba. Features are extracted manipulating the output of automatic tools, i.e., features in training potentially contain the same kind of errors that we will find when using Polaris in a real application.

Table 2: Polaris performance using different modules.
For testing purposes, we have fully annotated a bench mark that contains text outside the domain of the training data. This benchmark has been annotated without any sort of restriction on the kind of arguments that may encode a relation: any relation(from our inventory) holding between any two concepts is considered. This is a significant step towards realistic evaluation of semantic parsers: the parsers ouput is tested against a gold benchmark containing relations between concepts that were simply ignored during training. As a result, unlike evaluations of other tools for relation extraction, Polaris is tested against a much tougher benchmark. Results disabling different combinations of modules are reported in Table 2. Note that disabling the bracketer brings a drop of 3.75 in F-measure and disabling the domain and range filtering a drop of 7.95.
The performance of Polaris against standard corpora (e.g., PropBank, section 02–21 for training and23 for testing) is similar to the state of the art and we do not report it in this abstract because of the tight space contraints.
6 Discussion and Future Work
Polaris extracts relations from text and its output is provided in RDF, a standard for automatic reasoning and knowledge interchange. It is used at Lymba for a variety of real-world applications with high demand in industry, such as ontology creation, advanced question answering from heterogenous sources of data, textual entailments, and others. APIs have been developed to easily interact with Polaris from other applications. Currently, Polaris takes about 1second to process 5 KB of free English text.
Some issues remain unsolved and several improvements are scheduled. We plan to incorporate semantic primitives and expect a gain on improvement similar to the one brought by domain and range filtering. Incorporating primitives will fully integrate our proposal for an extended definition of semantic relations (Blanco and Moldovan, 2011).
Composing the relations provided by Polaris is another addition. Our framework for composing relations (Blanco and Moldovan, 2011) will facilitate the extraction of relations between concepts that are far away in a sentence which normally are not considered by a semantic parser, and we believe it should bring an improvement against the benchmark. Finally, we also plan to add an extra module to customize the relation inventory using inference axioms without modifying the current Polaris implementation.
References
Mithun Balakrishna, Dan Moldovan, Marta Tatu, and Marian Olteanu. Semi-Automatic Domain Ontology Creation from Text Resources. LREC 2010.
Eduardo Blanco and Dan Moldovan. Unsupervised Learning of Semantic Relation Composition. ACL-HLT 2011.
Eduardo Blanco, Hakki C. Cankaya, and Dan Moldovan. Composition of Semantic Relations: Model and Applications. COLING 2010.
Xavier Carreras and Lluıs Marquez. Introduction to theCoNLL-2005 shared task: semantic role labeling.
Hermann Helbig. 2005.Knowledge Representation and the Semantics of Natural Language. Springer.
Iris Hendrickx, Su N. Kim, Zornitsa Kozareva et al.SemEval-2010 Task 8: Multi-Way Classification of Semantic Relations Between Pairs of Nominals.
Dan Moldovan and Adriana Badulescu. A Semantic Scattering Model for the Automatic Interpretation of Genitives. HLT-EMNLP 2005.
Dan Moldovan, Marta Tatu, and Christine Clark. 2010.Role of Semantics in Question Answering. Semantic Computing. Wiley-IEEE Press.
Hoifung Poon and Pedro Domingos. 2009. Unsupervised semantic parsing. EMNLP 2009.
James Pustejovsky and Marc Verhagen. SemEval-2010Task 13: Evaluating Events, Time Expressions, and Temporal Relations (TempEval-2).
Josef Ruppenhofer et al. SemEval-2010 Task 10: Linking Events and Their Participants in Discourse.
Marta Tatu and Dan Moldovan. A semantic approach to recognizing textual entailment. HLT-EMNLP 2005.