

Group Dynamic Analysis and Multi-Modal Ontologies
Task Objectives
Co-reference resolution of entities and events both within and across documents is critical to connecting the dots during the analytic process. Further, being able to quickly understand information in the context of a new domain requires adapting tools and methods to that domain. In Connecting the Dots with Domain Awareness, Lymba proposes to develop algorithms that fuse information extracted across and within documents by exploiting the semantic and syntactic context of entities and events. A context is defined by the surrounding named entities, semantic relations, events, concepts, and linguistic structure. Further, Lymba will develop tools and algorithms to assist analysts in quickly porting their analytic environment to new domains. Due to its participation in the ARDA programs AQUAINT, NIMD, CASE, and DARPA’s GALE, Lymba has a suite of natural language processing tools and is well positioned to advance the state of the art in text understanding. Some key innovations of the Lymba proposed approach include: 1) Extracting deep semantics from text, 2) Semantic calculus as a vehicle for rapid domain customization, 3) Temporal and spatial analysis of events, 4) Cross and within document co-reference, 5) Inferring non-explicit information, and 6) Performing text understanding within domain contexts.
Task 1: Identify and Score Co-reference Links Between and Across Documents
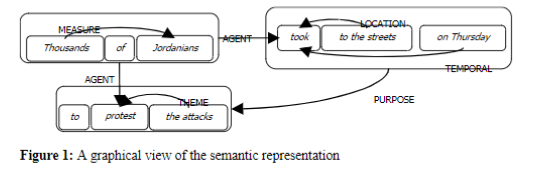
Lymba’s semantic parser Polaris extracts 26 types of relations that connect entities, events, and their arguments, forming a semantic context for describing concepts. .Figure 1 illustrates the rich semantic representation derived for the sentence “Thousands of Jordanians took to the street on Thursday to protest the attacks”. Additionally, EventNet, Lymba’s ontology of events from WordNet contains valuable information about the features of events and their actors. Each event has a frame consisting of slots corresponding to different properties, states, roles, and relations with different values and probabilities of occurrence that is based on the semantics extracted for a corpus of web and Wikipedia documents.
As part of the work for this task, Lymba will develop algorithms that take advantage of semantic relations, event frames, linguistic structure and lexical chains to link concepts and events together and provide a similarity score. As an example, events that have the same date and location, involve the same type of weapon, and have approximately the same number of casualties are likely to be the same event.
Task 2: Performing Temporal Analysis of Entities and Events
Lymba has done work to detect and normalize temporal expressions in text with the format of TIME(year, month, day, hour, minute, second), as an example the year 1930 is represented with: Time(BeginFn(x3),1930,1,1,0,0,0), Time(EndFn(x3),1930,12,31,23,59,59)
This representation makes it possible to do temporal reasoning using A SUMO Knowledge Base of temporal reasoning axioms for representing time points, time intervals, Allen primitives, and temporal functions. As an extension to this work, Lymba will attach normalized temporal contexts to events so they can be ordered in a timeline and used to infer causation chains. Lymba will also work to improve the temporal detection module to include fuzzy time references and to propagate temporal constraints across the co-reference links from Task 1.
Task 3: Customize Semantic Relations Automatically by Using a Semantic Calculus
In order to increase the connectedness of the semantic relations found in text Lymba’s semantic parser includes Semantic Calculus operations, a formal framework for manipulating semantic relations and using inference axioms to generate new implicit information. An axiom is defined as a set of relations, called premises and a conclusion, which is the resulting new relation. Given the premises, an axiom unequivocally yields a semantic relation that holds as conclusion. The composition operator is the basic way of combining two relations to form an axiom. This Semantic Calculus consists of logic operators for symmetry, reflexivity, transitivity, dominance, submissivity, asymmetry, etc. The calculus can combine relations using the ISA, temporal, and causal chains of relations and other semantic relations that the concepts along these chains belong to. This Semantic Calculus, along with generally-applicable semantic rules learned from resources like WordNet and SUMO, is useful for analysis by generating extra semantic information (i.e. facts, assertions, and inference rules), enhancing the search space, demonstrating missing information and suggesting links that may be otherwise missed. As an example, the semantic parser extracts the following relations from the sentence
“Courtaulds Chairman and Chief Executive Sir Christopher Hogg will remain in both posts at the surviving chemical company after the spinoff”:
PART-WHOLE (CourtauldsChief Executive, Courtaulds)
IS-A (Sir Christopher Hogg, CourtauldsChief Executive) and others.
An example of new knowledge generated using a semantic calculus axiom is: IS-A(x1,x2) ○PART-WHOLE(x2,x3) →PART-WHOLE(x1,x3), which, given the set of semantic relations extracted for the whole sentence, derives a new semantic link PART-WHOLE(Sir Christopher Hogg, Courtaulds). This same calculus mechanism can be extended to rapidly customize semantic relations for specific domains.
Lymba proposes to develop methods for rapid customization of the set of semantic relations and semantic parser as needed. Semantic calculus can be applied to infer new and specialized relations. Using this approach has the advantage of not having to train a new semantic parser for the new semantic relations. Instead, taking as input the set of 26 relations, we generate domain specific relations without modifying any other tool:

Consider we need the new relation ARRESTED(x, y), which intuitively encodes the relation between two animated concrete objects x and y, where x arrested y. We can infer the relation by using the following axiom: AGENT(x,y) ○THEME-¹(y,z) →ARRESTED(x,z), provided that y is an arrested concept. A simple way of checking if a given concept is of a certain kind, is to check WordNet. Collecting all the words belonging to the synset arrest, we get the following list of arrested concepts: apprehension, catch, collar, pinch, taking into custody, nail, apprehend, pickup, nab and cop. Using lexical chains the list could be further improved.
More examples of axioms for generating customized semantic relations are the following:
AGT(x; y) ○ THM-¹(y; z) & [y is arrested concept] → ARRESTED(x, z),
THM(x; y) ○ AT-LOC(y; z) & [y is arrested concept] → ARRESTED-AT(x, z),
AGT(x; y) ○ AT-LOC(y; z) & [y is banking activity ] → BANKS-AT(x, z) and
POS(x; y) ○ AT-LOC(y; z) & [y is account concept] → BANKS-AT(x, z).
Task 4: Text to RDF Conversion
In order to make the semantic information extracted from text readily available to third party reasoning systems, Lymba will develop algorithms to map the semantic relations and the concepts into the W3C standard for the Resource Description Framework (RDF). Lymba already has a complete RDFS schema for the information extracted by it tools and would extend this to work with the information extracted for co-reference links and scores, and for domain tailored semantic relations.
B. Technical Summary and Task Deliverables
Lymba has been an active contributor to the natural language processing community for more than 10 years and has a rich set of capabilities that can be leveraged to build new algorithms and tools to: 1) Fuse information extracted from textual sources of intelligence in order to help analysts connect the dots, and 2) Rapidly customize semantic relations and information extraction for new domains. The deliverables for this project include: 1) Algorithms for cross and within document co-reference that use semantic relations and EventNet as features for scoring the similarity of two or more entities and events. 2) Algorithms for temporal event detection, normalization, and ordering. 3) Algorithms for semi-automating rapid customization of semantic relations for new domains, and 4) Algorithms to extend Lymba’s existing RDF representation of semantics extracted from text with cross document co-reference links and scores, as well as the customized relations generated for new domains.